Scissorhands: Exploiting the Persistence of Importance Hypothesis for LLM KV Cache Compression at Test Time
December 7, 2023·, ,,,,,
,,,,,
Zichang Liu
Aditya Desai
Fangshuo Liao
Weitao Wang
Victor Xie
Zhaozhuo Xu
Anastasios Kyrillidis
Anshumali Shrivastava
Abstract
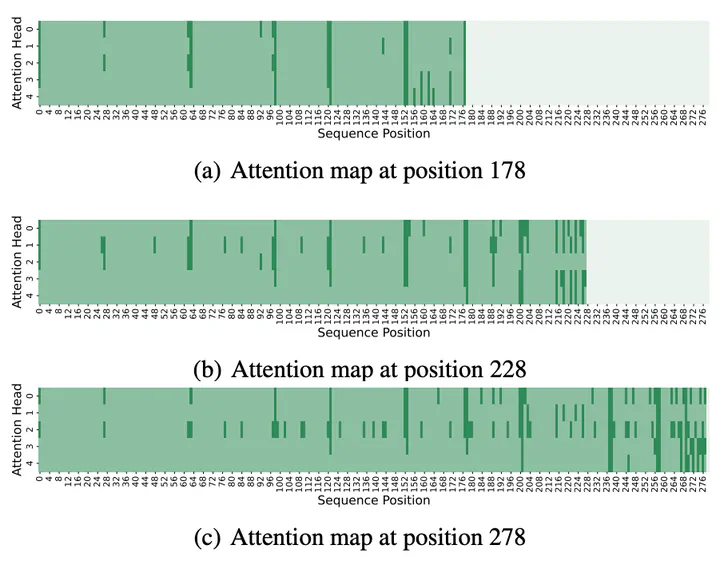
Large language models(LLMs) have sparked a new wave of exciting AI applications. Hosting these models at scale requires significant memory resources. One crucial memory bottleneck for the deployment stems from the context window. It is commonly recognized that model weights are memory hungry; however, the size of key-value embedding stored during the generation process (KV cache) can easily surpass the model size. The enormous size of the KV cache puts constraints on the inference batch size, which is crucial for high throughput inference workload. Inspired by an interesting observation of the attention scores, we hypothesize the persistence of importance: only pivotal tokens, which had a substantial influence at one step, will significantly influence future generations. Based on our empirical verification and theoretical analysis around this hypothesis, we propose SCISSORHANDS, a system that maintains the memory usage of KV cache under a fixed budget without finetuning the model. We validate that SCISSORHANDS reduces the inference memory usage of the KV cache by up to 5× without compromising model quality. We further demonstrate that SCISSORHANDS can be combined with 4-bit quantization for further compression
Type
Publication
Conference on Neural Information Processing Systems, 2023